基本知识
(一)绘图
导入模块
#导入模块 |
输入及图表属性
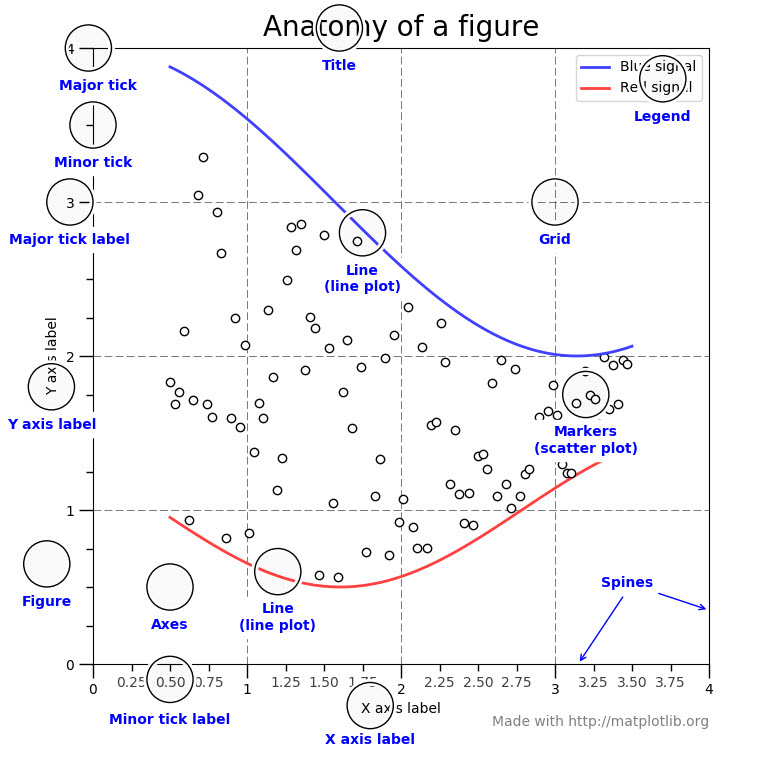
所有绘图功能都期望np.array或np.ma.masked_array作为输入,类似“数组”的类.例如pandas数据对象,np.matrix可能会或可能不会按预期工作。最好用np.array在绘图之前将这些转换为对象。
例如,转换一个 pandas.DataFrame
a = pandas.DataFrame(np.random.rand(4,5), columns = list(‘abcde’))
a_asndarray = a.values
和隐蔽的 np.matrix
b = np.matrix([[1,2],[3,4]])
b_asarray = np.asarray(b)
例子
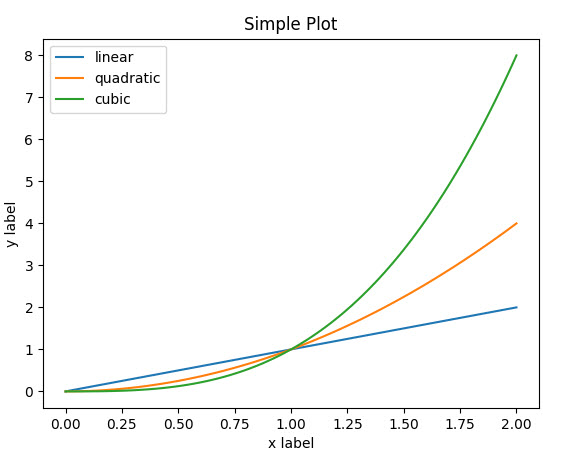
例子1:同一张图画多根曲线
x = np.linspace(0, 2, 100) |
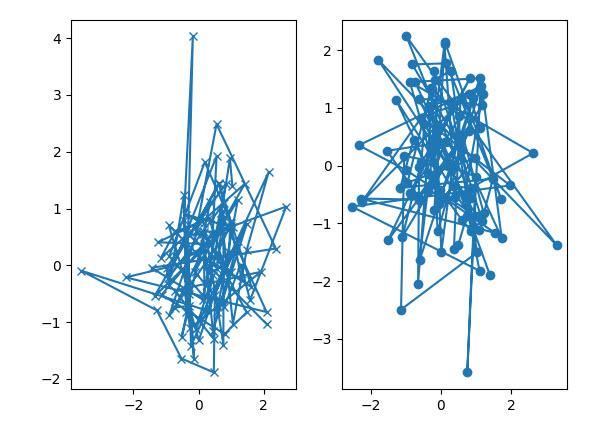
例子2:重复画图
def my_plotter(ax, data1, data2, param_dict): |
(二)numpy
属性
ndarray.ndim
数组的轴数(尺寸)。
ndarray.shape
数组的大小。这是一个整数元组,表示每个维度中数组的大小。对于具有n行和m列的矩阵,shape将是(n,m)。shape因此,元组的长度 是轴的数量ndim。
ndarray.size
数组的元素总数。这等于元素的乘积shape。
ndarray.dtype
描述数组中元素类型的对象。可以使用标准Python类型创建或指定dtype。此外,NumPy还提供自己的类型。numpy.int32,numpy.int16和numpy.float64就是一些例子。
ndarray.itemsize
数组中每个元素的大小(以字节为单位)。例如,类型的元素数组float64有itemsize8(= 64/8),而其中一个类型complex32有itemsize4(= 32/8)。它相当于ndarray.dtype.itemsize。
ndarray.data
包含数组实际元素的缓冲区。通常,我们不需要使用此属性,因为我们将使用索引工具访问数组中的元素。
创建数组
从常规Python列表或元组创建数组:np.array()
创建全零数组:np.zeros( (3,4) )
创建数字序列:np.arange( 10, 30, 5 ) (接受float参数)
第三个参数是步进长度
当arange与浮点参数一起使用时,由于有限的浮点精度,通常不可能预测所获得的元素的数量。出于这个原因,通常最好使用linspace作为参数接收我们想要的元素数量的函数
np.linspace( 0, 2, 9 ) 第三个参数是总数
数组切片
a[0:2]: –a[0] a[1]
注意:留左不留右
resharp(,): 转换数组的大小
(三)读写文件
由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try … finally来实现:
try: |
或者用
with open('/path/to/file', 'r') as f: |
(四)读函数
python文件对象提供了三个“读”方法: read()、readline() 和 readlines()。每种方法可以接受一个变量以限制每次读取的数据量。
read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。如果文件大于可用内存,为了保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。
readlines() 之间的差异是后者一次读取整个文件,象 .read() 一样。.readlines() 自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for … in … 结构进行处理。
readline() 每次只读取一行,通常比readlines() 慢得多。仅当没有足够内存可以一次读取整个文件时,才应该使用 readline()。
注意:这三种方法是把每行末尾的’\n’也读进来了,它并不会默认的把’\n’去掉,需要我们手动去掉。
In[4]: with open('test1.txt', 'r') as f1: |
绘图脚本编写
待解决问题
Spyder中其他路径的文件读取不到
添加文件路径
import sys
sys.path.append("Z:\liqinxing\test_photo\sdm660_ipc")字符串如何批量转数字 ——map函数
一行字符串如何转数组 ——split函数
一维数组如何转二维数组 ——resharp
三维数组如何画图 ——引入mpl_toolkits.mplot3d
脚本如下
import sys |





